Computer Graphics (GRK)
Lecture XI
Image storing
Generated images must be stored in some form. Specific file formats are used for this purpose. Before we present a few popular formats we will discuss the compression - compression methods enable the reduction of file size, thus reduce required memory capacity and also reduce image transmission time. In practice all formats allow using compression.
Image compression
Finished rendered images are stored in the form of bitmaps. The memory capacity required to store single image is significant. For example to store image with pixel resolution 1920 x 1080 using 24 bits per pixel we need about 6,22 MB. Thus the need of image compression arises and so storing them in such form that reduced as much as possible the memory capacity necessary to store the image.
In image compression we may distinguish two approaches. One assume that the compression have to be lossless. It means that the image after compression and then decompressed should look exactly the same as an original image - during the compression process no information is lost. It assumption significantly reduces the compression level possible to obtain. In practice lossless compression methods allow the compression level (the ratio of memory capacity before compression to the required capacity after compression) in the range of a few.
In the another approach to compression we allow some information losses during the process of compression-decompression. Then we speak about lossy compression. In such case compression level may achieve the values in the range of several dozen. In lossy compression we strive to remove the information with small influence on image interpretation So insignificant details are removed.
In next part of the lecture we will discuss example of lossy and lossless compressions.
Lossless compression
Just the simplest method of lossless compression is a method of coding the series of characters known as RLE method. The essence of this method relies on finding a sequence of identical elements and storing their value and number of occurrence repetition. Let us assume that the pixels in monochrome image (with grey levels) are represented on bytes and a series of pixel in the image is such as in Fig. XI.1a. This series may be written according to given rule in the way shown in Fig. XI.1b. In each pair of the numbers the first means repetition number and the second the value of pixel. It is obvious that having compressed sequence and remembering the rule of compression we are able to perform decompression and restore accurately original series of pixels.

Fig. XI.1. The example of RLE compression method. a) Information before compression, b) compressed information
Effectiveness of RLE compression is great when the long series of the same values appears. However if there are single values then instead of profit, the losses may occur. (In some implementation the solutions for such special cases are included). Usually, in particular implementations we compress separate rows of the image. It is not a general rule. There exist solutions where the columns of image are coded, or a sequences chosen by ZigZag method (see Fig. XI.4).
Let us pay attention to colour images coding. If the pixel is represented using three primary colours R, G and B, then the image may be written as a sequence of RGB triplets representing next pixels. But it also may be written as three separate sequences each containing only one primary, respectively only R component, only G component, and only B component of next pixels (see Fig. XI.2). It may be noticed that in the second case the effectiveness may be greater, due to the greater chance to meet longer series of identical values in the series of the same component (forming so called R, G and planes).

Fig. XI.2. The influence of data ordering on effectiveness of compression. a) pixel order, b) order according to component colours
In general the RLE compression method allows the compression levels in the range 2 : 1, 3 : 1. Obviously the compression level depends on given image - fore some images it may greater and for the others may be less. It is a characteristic feature of all compression methods.
Among the other methods of lossless compression methods the Huffman method should be mentioned, where the codes of different length are used. For the pixels most frequently appearing in the image shorter codes are assigned.
The method works as follows. At first we test how many pixels in the image has specific colour (for example by preparing image histogram). Then the percentage of participation is ordered from the greatest to the smallest value and an auxiliary tree is created. Among the ordered percentage participation of colours we find two values which has minimal value of a sum. They are joined and founded sum is assigned to the created tree node - the component values forming the sum are removed. The procedure is repeated for the remaining set of values. Tree creation ends when we get to the root. After creation of tree, in each tree node we assign values 0 or 1 to the edges. Then starting from the root we find the shortest paths leading to the leafs. For each path the values assigned to the edges are registered. The obtained series of binary values are the codes which in compression process will be assigned to the colours associated with specific tree leaf.
During the compression process we scan next pixels of the image and assign new codes to them. The codes are added to compressed sequence. Let us notice that in most cases the original pixel code (for example 8 bit) is substituted by shorter code. It is important that for the pixels with most frequent colours the shortest codes are assigned. The resultant compressed code should be necessarily equipped with coding table.
Decompression process is simple. We look at compressed series from the beginning and test whether the bit sequence corresponds to any code from code table. If so in restored image we place original pixel colour before compression. The procedure is repeated until full original image is restored. In the whole process compression - decompression no information is removed. Obtained compression levels are in the range a few to one.
Example
Compress with Huffman method the image shown below. Pixels are coded on 8 bits.
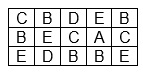
Let us start from finding the histogram.

Then we create Huffman tree and find new codes for particular pixels.

Then we prepare compressed image sequence and add the coding table
A-000, B-11,C-01,D-001,E-10
Notice. In this simple example compression level is small - not taking into account the code table is equal approximately to 2.
Spośród innych metod kompresji bezstratnej należy wymienić metodę słownikową LZW. Istotną cechą tej metody jest to, że w czasie kompresji obrazu jest równocześnie zapisywana informacja o słowniku i nie potrzeba go niezależnie dołączać do postaci skompresowanej. Słownik ten jest odtwarzany stopniowo czasie dekompresji. Ponieważ metoda LZW była przez wiele lat objęta ochroną patentową, to często wykorzystywano w praktyce wcześniejszą wersję tej metody LZ77, która nie była objęta ochroną patentową.
Lossy compression
One of the most frequently used lossy compression methods is JPEG. It is very complex method, so we will present only the general concept of this method. At first the image is divided into sub-images (blocks) of the size of 8x8 pixels. Each block undergoes the compression independently. The stages of compression process are shown in Fig. XI.3.

Fig. XI.3. Block diagram of JPEG compression method
In the first step the conversion from RGB model to model YCbCr (digital version of the model YUV) takes place. The next steps of algorithms are made independently for luminance component Y and for chrominance components Cb and Cr. Calculations for luminance Y are done with greater accuracy than for Cb, Cr components – we use the fact that human eye is more sensitive to luminance changes than to the change of colour.
For the block of values of luminance Y with the size 8×8 we perform cosine transformation and as a result we get new set of 64 numbers - coefficient of cosine development. The following equation is used:
$$S_{vu}=1/4C_uC_v∑↙{x=0}↖7∑↙{y=0}↖7 s_{yx}\cos{(2x+1)uπ}/16\cos{(2y+1)vπ}/16$$
where $s_{yx}$ are the original data from the table with coordinates yx and $S_{vu}$ are coefficients obtained as the results of cosine transformation written in the table with coordinates vu. Coefficients $C_u$ and $C_v$ are equal to $1/√2$ when $u,v=0$ and equal to 1 in the opposite case.
In next step so called quantisation is done. The purpose is to exchange as great as possible number of coefficients of transformation for zero. In general the point is that among the coefficients of transformate there are such that convey great number of information about the image and such that convey very little information. The lasts may be eliminated without significant loses in general image quality. Their influence is so small, that the observer may even do not notice the changes in image due to removal of this coefficients.
The quantization is done in the following way. We use auxiliary table 8x8 containing properly chosen values. Then in turn we divide the coefficients from the table obtained during transformation by corresponding coefficients from auxiliary table. The first element from the table of coefficients of transformation is divided by the first element from auxiliary table, then the same is done to second elements and so on. The results are down rounded. The elements in auxiliary table are chosen in such way, that in resultant table possible great number of zeroes grouped in the lower right corner of resultant table appear. Due to quantisation we obtain compression of the information. The operation is not reversible.
The table obtained as a result of quantisation is subjected to coding by RLE method and then Huffman coding. The series of values from resultant table is scanned in ZigZag order and coded by RLE method what is shown in Fig. XI.4. Such order is accepted for the purpose of obtaining long series of zeroes grouped in lower right corner of the table. Let us notice that the series does not include the element from the upper left corner marked as DC It is coded parallel with respective elements for another 8x8 blocks that the image under compression consists of.

Fig. XI.4. Scanning of table elements in ZigZag order
During decompression we act in reverse order. At first we perform Huffman decoding, then the RLE decoding. The restored table is subjected to reverse operation with respect to quantisation (with the use of auxiliary table) it is obvious that we can not restore the coefficient that were zeroed. The restored table of coefficient of cosine transformation is subjected to reverse cosine transformation. Finally the conversion from YCbCr model to RGB model is performed.
The JPEG compression method achieves compression levels 20:1 – 30:1, with practically invisible distortions of the image restored after decompression. At greater compression levels the changes become visible. (The compression level change is obtain by changing the coefficients of an auxiliary table used in quantisation process). It is shown in Fig. XI.5 where the image of Lena was compressed 20 :1 and 50:1. The images after compression are shown at right side, upper and lower place respectively. At the lower left side the difference image between original and the image after decompression 20:1 is shown. Here we can see the information that was removed in compression - decompression process.



Fig. XI.5. a) Image of Lena, b) image compressed 20:1 after decompression, d) image compressed 50:1 after decompression, c) difference image between image a) and b)
Above the basic version of JPEG standard, most frequently used in practice is presented. In fact full standard includes 29 different compressions including the lossless compression. In 2000 year the next version of compression JPEG2000 was developed, where it was assumed that the compression is done directly on the whole image and wavelet transformation is used. But this standard was not accepted in practice.
At the end we add that the discussed above compression methods are applied for compression of single still images. During compression a sequence of images (such as animation) the different methods are used for example such as in MPEG standards.
File formats
After image generation the problem arises how to store and transfer such image. Accepted way of image representation should enable restoring the image read from the memory or after finishing the transmission. At the same time the representation should be economical, mainly due to transfer speed limits or limited memory capacity. It should be elastic enough to store information about quite different types of images, starting from small black and white images and ending with high resolution colour images with great number of bits devoted to represent pixel colour.
Up to now no uniform representation has been developed. It is difficult to fulfil such contradictory requirements. Moreover the companies push the policy to have their „own” standards. In result many different methods of image representations, so called formats have been developed.
In each format we may distinguish following parts: the heading, description of the image, specific representation of image content, and additional supporting informations. In the heading usually general information about format (enabling the identification of format), about image origin, about the author etc. In description of the image the data characterizing the image as a whole are contained: the size, resolution, number of bits per pixel, colour representation, the method of compression etc. Image content part include information about an image written according to accepted convention in the format. Additional information may contain the information concerning the way of displaying or printing the image - in particular the device profile of the device that capture the image may be included.
Some of the formats are used in limited range, some of them became more popular. Below we limit ourselves to present a few of the most popular formats, giving some most characteristic informations. In discussed formats the image is represented as bitmap (raster formats, bitmap formats). But we also signal that there are vector formats, enabling storing the information about the image as series of graphics commands and data, needed to create an image in pixel form (SVG or CDR formats). Moreover we will signal the existence of formats enabling representation of a sequence of images in the form of animation (for example .avi)
The obvious problem of conversion between formats arises due to existence of many different formats. In practice the problem is solved in two manners. The first solutions is such that the manufacturers of graphics programs includes the possibility to import images written in a few formats and also the possibility to export them as well. The second solution is such that independent conversion programs between chosen formats are made available. Let us pay attention to the fact as far as the conversion between formats intended to store images in the form of bitmaps is relatively simple, the conversion in the case of vector formats is much more complex.
Format TIFF. Format TIFF (Tag Image File Format) is very elastic. In enables storing information about bitmap images with different resolutions both black and white and colour (up to 24 bits per pixel). Different colour models may be used (RGB, CMYK, YCbCr etc.). The information about pixel transparency may be stored. Different compression methods are allowed (no compression, RLE, LZW, JPEG compression and others). The additional information for reproduction the image on different devices may also be included.
Format GIF. In GIF (Graphics Interchange Format) format the lossless compression LZW is used. It allows the images with at most 256 colours (8 bit per pixel). It enables definition of background transparency. The file may contain many images which gives the possibility to store simple animations.
Format PNG. Format PNG (Portable Network Graphics). Format uses good lossless compression based on LZ77 method. After LZ77 compression the resultant sequence is compressed by Huffman method.
Format allows using up to 48 bit for pixel representation.
Format PNG allows five method of pixel colour representation. The first is representation in the form of triplet RGB.
The second allows using colour Look up Table. In such case the information about specific pixel is an entry to Look up Table (which must be attached to the file).
In the case of monochrome images it is possible to use grey scale.
The transparency effect may be obtained by using α channel which enables joining the image with the background. In this case beside the RGB values the value of auxiliary parameter α is stored. The number of bits devoted to store information about component colours R,G,B and α is the same (8 or 16). If the value of parameter α is equal to zero the pixel is fully transparent, so the background is fully visible. With maximum value of parameter α the background is totally obscured be pixel. In intermediate cases the colour of pixel P is mixed with the background colour B by the principle (αP + (1 - α) B)).
The last way of colour representation relies in including the α coefficient it the case of monochromatic images. Then the value of pixel and value of coefficient α are stored.
In PNG format there is a possibility to include the information about the profile of the device which generated the image. This information is important to Colour Management Systems.
It is worth noting that some mechanism relevant to resistance to transmission errors are embedded in PNG format.
Format JPG. Most of described format allow lossless compression. Among the formats using lossy compression the most popular became format JPEG, which uses JPEG compression method to compress and store images. This format is most frequently used for storing and transmission of the images.
Format SVG. Format SVG (Scalable Vector Graphic) enables storing the image in vector form. It is possible to store static images and animations. The format is not assigned to any particular graphics program.
Some of graphic files may be edited freely after opening. Raster formats such as PNG, GIF, JPG has no such feature.
In this lecture we raised an issue of image storing. The image generated sometimes prepared with large workload must be stored in specific file. The form is not irrelevant. The image must let it open directly by the image creator and also by the another users who get the image transferred. The problem is solved by different file formats, that in general allow using compression of the image. During the lecture we have learned a few basic compression methods both lossless and lossy.
Questions and problems to solve.
-
Explain the compression problem and compare lossless and lossy compression methods.
-
Using the result of compression got in the example illustrating Huffman method restore original form of compressed image.
-
Perform Huffman compression of following image. Pixels are coded on 8 bits.

-
Explain why at final stage of JPEG compression we use scanning of table with ZigZag method.
-
Name basic features of PNG format.